DeepSeek AI 推出的超高效 R1 模型,曾引發全球科技股市值蒸發近一萬億美元的震盪,並徹底改變了人工智能產業的競爭格局。為應對這一挑戰,OpenAI 於上週五緊急發佈了 o3-mini模型,對撼 DeepSeek 的 R1 模型。DeepSeek 的 R1 模型以其低廉的計算成本卻能達到頂尖效能,震驚了整個 AI 行業。
即加入CFTime TG 討論區!想掌握最新加密市場動態與 AI 新聞與資訊,更能隨時獲得免費 web 3入場券!
OpenAI 在官方博客文章中宣佈:「我們推出 OpenAI o3-mini,這是我們推理系列中最新、最具成本效益的模型,現已於 ChatGPT 和 API 平台上架。」 「這款於 2024 年 12 月預覽的強大且高速模型,突破了小型模型的效能極限……同時保持 OpenAI o1-mini 的低成本和低延遲。」
為推廣其全新推理模型系列,OpenAI 首次免費向用戶提供推理功能,並將付費用戶的每日訊息上限從 50 條提升至 150 條(增幅三倍)。
o3-mini模型 創造力相對較弱 但更擅長解決複雜問題
與 GPT-4o 和 GPT 系列模型不同,「o」系列 AI 模型專注於推理任務。其創造力相對較弱,但內建思維鏈推理功能,使其更擅長解決複雜問題、修正錯誤分析,並編寫結構更佳的程式碼。OpenAI 主要擁有兩個 AI 模型系列:生成式預訓練變換器 (GPT) 和「Omni」 (o)。
GPT 系列如同家族中的藝術家,擅長角色扮演、對話、創意寫作、摘要、解釋、腦力激盪、聊天等;而「o」系列則如同家族中的科學家,雖然不擅長敘事,卻精於編碼、解算數學方程式、分析複雜問題、逐步規劃推理過程、比較研究論文等。
全新的 o3-mini 模型分為低、中、高三個版本。用戶可根據需求選擇不同版本,以換取更精準的答案,但相對地,開發者需要支付更多「推理」費用(按代幣計費)。
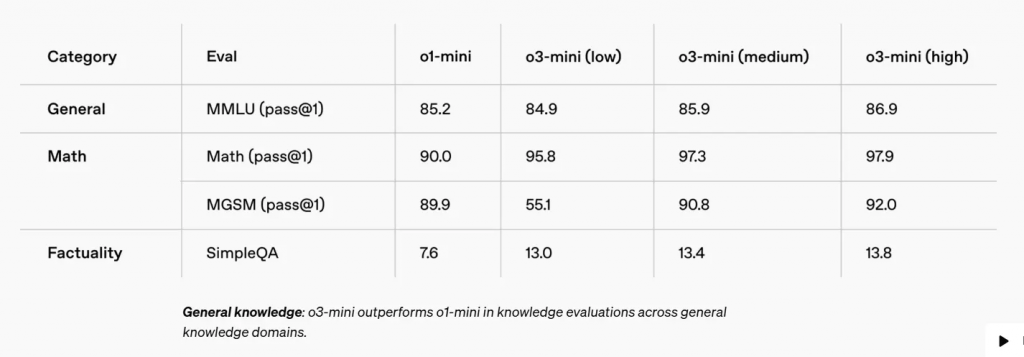
就效率而言,OpenAI o3-mini 在一般知識和多語言思維鏈方面的表現不及 OpenAI o1-mini,但在編碼和事實性等其他任務上的得分則更高。o3-mini 中型和大型版本則在所有基準測試中均超越 OpenAI o1-mini。
DeepSeek R1 模型以極低的計算能力卻能超越 OpenAI 旗艦模型的表現,引發了科技股拋售潮,導致美國市場市值損失近一萬億美元,其中英偉達單獨市值蒸發 6000 億美元,投資者對其高價 AI 晶片的未來需求產生疑慮。
DeepSeek 的成功源於其在模型架構上的創新方法。與美國公司傾向於投入更多計算能力不同,DeepSeek 團隊致力於優化模型的資訊處理流程,從而提升效率。隨著中國科技巨頭阿里巴巴推出效能更強的 Qwen2.5 Max 模型(其基礎模型與 DeepSeek 相同),競爭壓力進一步升級,預示著中國 AI 創新浪潮的到來。
OpenAI o3-mini 運行速度比前代提升 24%
OpenAI o3-mini 則試圖再次拉大差距。新模型運行速度比前代提升 24%,在關鍵基準測試中與舊模型不相上下甚至超越,同時運作成本更低。
在定價方面,OpenAI o3-mini 的價格為每百萬個輸入代幣 0.55 美元,每百萬個輸出代幣 4.40 美元,雖然高於 DeepSeek R1 的 0.14 美元和 2.19 美元,但已縮小了與 DeepSeek 的價格差距,並大幅降低了與 OpenAI o1 相比的成本。這可能是其成功的關鍵因素。OpenAI o3-mini 為閉源模型,而 DeepSeek R1 則為開源,但對於願意在託管伺服器上付費使用的用戶而言,o3-mini 的吸引力將取決於其應用場景。
在 AIME 數學問題基準測試中,OpenAI o3-mini 中型版本得分 79.6 分,DeepSeek R1 得分 79.8 分,僅次於 OpenAI o3-mini 大型版本 (87.3 分)。
在其他基準測試中,例如衡量不同科學領域能力的 GPQA 分數,DeepSeek R1 為 71.5 分,o3-mini 低配版為 70.6 分,o3-mini 高配版為 79.7 分;在編碼任務基準測試 Codeforces 中,R1 位於第 96.3 百分位,o3-mini 低配版位於第 93 百分位,o3-mini 高配版位於第 97 百分位。因此,不同模型之間的差異取決於任務而有所不同。
OpenAI o3-mini 與 DeepSeek R1 的測試比較
我們進行了多項測試以比較兩款模型的表現。其中一項測試為基於 Github BIG-bench 數據集的間諜遊戲,用以評估多步驟推理能力。OpenAI o3-mini 在此測試中表現不佳,得出錯誤結論,將兇手誤判,而 DeepSeek R1 則正確地判斷兇手。
然而,o3-mini 在不涉及數學的邏輯語言任務中表現良好。例如,要求其撰寫五個以特定單詞結尾的句子,o3-mini 能夠理解任務、評估結果並提供正確答案,其思考時間為四秒,並自行修正了一個錯誤答案。
在數學方面,o3-mini 表現出色,能夠快速解決一些被認為極其困難的問題。例如,DeepSeek R1 需要 275 秒才能解決的複雜問題,o3-mini 僅需 33 秒即可完成。
總而言之,OpenAI 的 o3-mini 模型展現出一定的競爭力,但 DeepSeek R1 的挑戰依然存在,雙方在 AI 領域的競爭將持續升溫。