

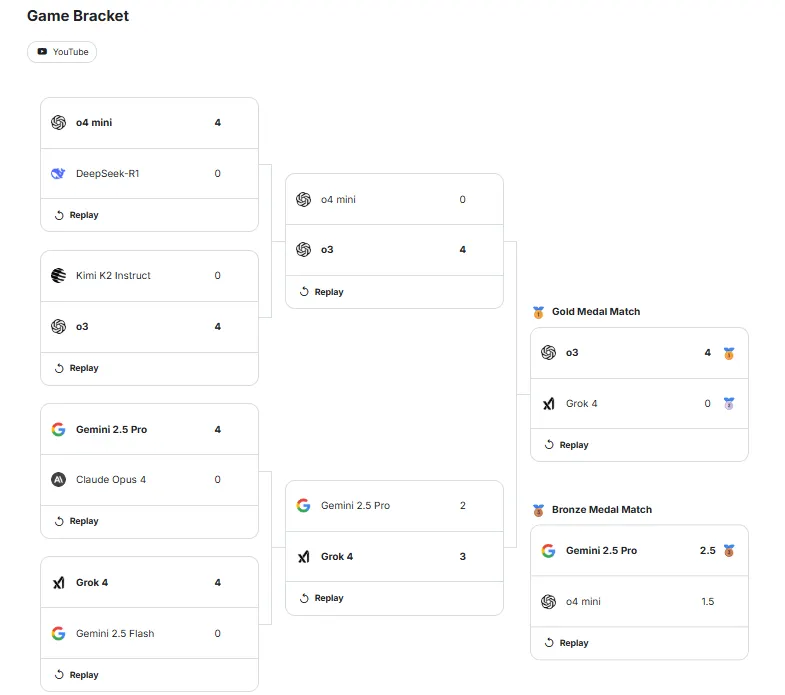
Sam Altman完勝馬斯克!日前Google Kaggle Game Arena舉辦了一場備受矚目的AI西洋棋表演賽,Sam Altman 的 OpenAI o3 模型(已隨 GPT-5 發布而停止使用)以四比零的絕對優勢擊敗馬斯克的 xAI Grok 4 模型, GPT西洋棋碾壓Grok4,引發業界對大型語言模型(LLM)在專業遊戲領域能力的重新思考。
即加入CFTime TG 讨论区!想掌握最新加密市场动态与 AI 新闻与资讯,更能随时获得免费 web 3入场券!
這場為期三天的比賽(8月5日至7日)別具特色,參賽的通用型聊天機械人,例如 OpenAI o3 和 xAI Grok 4,均未接受任何專業的西洋棋訓練,僅依靠從網路上學習到的知識進行比賽。 比賽結果顯示,這些號稱接近人類智慧水平的 AI,其西洋棋水平卻令人大跌眼鏡。世界西洋棋冠軍 Magnus Carlsen 將兩款 AI 的棋力評估為約 800 ELO,遠低於他本人 2839 分的 Elo 等級,甚至不如近期才學會規則的業餘玩家。 Carlsen 形容 AI 的表現為「在非常好的棋步和令人費解的連續棋步之間搖擺不定」,甚至戲稱 Grok 的走法像是「在玩國王山」。
比賽過程充斥著低級失誤。Grok 在首局比賽中輕易送出重要棋子,之後更在劣勢下持續交換棋子,雪上加霜。第二局比賽,Grok 嘗試執行「毒兵」策略卻抓錯棋子,導致皇后被俘。第三局比賽,Grok 建立了看似穩固的陣型,卻在中局連續損失多枚棋子。
值得注意的是,Grok 在與 o3 對決之前表現亮眼,甚至獲得西洋棋大師 Hikaru Nakamura 的讚譽:「客觀地說,Grok 到目前為止絕對是最好的。」 然而,在與 o3 的比賽中,Grok 的表現卻急轉直下。 儘管 o3 在第四局比賽早期也犯下重大失誤,但最終仍憑藉穩定的殘局處理能力取得勝利。 Nakamura 評論道:「Grok 在這些比賽中犯了太多錯誤,但 OpenAI 沒有。」
比賽結果與 Musk 在 X 平台上發表的言論形成鮮明對比。 他在 Grok 早期表現強勢後聲稱,其 AI 的西洋棋能力僅為「副作用」,xAI「幾乎沒有在西洋棋上下功夫」。 此番言論顯然與比賽結果相悖。
本次比賽與國際象棋大師 Levy Rozman 今年早些時候舉辦的比賽有所不同。Rozman 的比賽中,AI 頻頻出現違規走法、棋子召喚和錯誤計算等問題,最終由專門設計的西洋棋 AI Stockfish 奪冠,當時 Altman 的 AI 也在半決賽中擊敗了 Musk 的 AI(2比0)。 而本次比賽則增加了規則,AI 若四次走非法棋步則直接判負,有效避免了此類情況。 Google 的 Gemini 模型則獲得第三名。
比賽結果顯示,即使是號稱接近人類智慧水平的 LLM,在需要專業知識和策略的遊戲領域仍然存在明顯的局限性。 Carlsen 指出,AI 更擅長計算已損失的棋子數量,而非實際將死對手,理解物質優勢卻無法將其轉化為勝利。 這也再次提醒人們,儘管 AI 技術快速發展,但距離真正的人工智慧仍有相當的距離。 目前,AI 對人類的威脅,至少在西洋棋領域,尚不足為慮。


